


Phonetics in Elastic(Search)
One of the classical issues when writing is misspelling based on phonetics, I can for sure speak about myself and my endless confusions…

One of the classical issues when writing is misspelling based on phonetics, I can for sure speak about myself and my endless confusions between feature and future, bit and beat and thought and through.
This issues are not only in english, if you are living, or learning german, you might find yourself with words like Bar (Bar) and Bär (Bear), similar words, slightly different phonetics, but certainly total different meaning.
With the basic idea in mind that people don’t write words completely ok, search engines like Elasticsearch and Solr, include support for phonetic algorithms. This algorithms are used to extend the indexer, or query, text with it’s approximate phonetic representation, and like this increate the recall, at expenses of losing precision.
In this entry we will see how Elasticsearch handles phonetics, but a very similar thing will also be possible with the other big open source search engine Solr.
Getting started
Elasticsearch has no phonetics support out of the boy, so before we can start playing with it, we’ll need to install the analysis phonetic-plugin, you can do this with this command:
bin/elasticsearch-plugin install analysis-phonetic
This plugin must be installed in every node of the cluster.
From now on you can use the phonetic token filter to add this capability to an analyzer.
What can you do with the Phonetic Token Filter?
As introduced before this token filter will extend the previously broken chunks of text with their approximate phonetic representation, to do this it uses a list of encoders:
metaphone(default), doublemetaphone, soundex, refinedsoundex, cologne, nysiis, beidermorse, daitch_mokotoff, and more.
To know more about the details of this methods you can check the great wikipedia page about phonetic algorithms.
In this entry we’ll use the Metaphone algorithm created by Lawrence Philips in 1990, focused on the english language. If you are operating in a non english language setup, you can check the Cologne algorithm for german or the Beider Morse that can actually handle more than one language.
Enabling phonetic search
First step to enable phonetic search is to create a custom analyzer that include the phonetic token filter as part of it’s processing chain. You can do that during your index mapping definition, should looks like:

this new index will encode every word also with the phonetic representation created with the metaphone algorithm. There is also the option, see replace, to force the filter to ignore the incoming token, and only output the new phonetic token.
All words indexed in this index will also include phonetic information, we can explore a few examples of this tokens if we leverage the _analyze api.
For example if we see the tokens generated for the words feature and future:
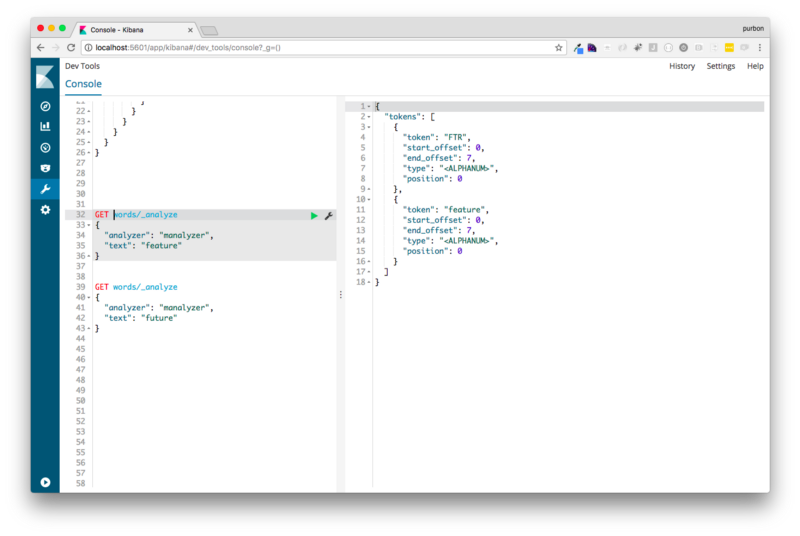

we can see how both words generate the same token “FTR”, a search using this analyzer will match both words ’cause they generate the same token. We can see a similar example with the words bit and beat, or Bar and Bär, try it.
Recap
Elasticsearch provides their users with a very rich set of options to setup a great search engine, in this entry we have introduced the phonetic capabilities through the phonetic analysis plugin.
We clearly notice the trade-off of using such a plugin, if we are introducing phonetic matching in our analysis chain our search engine will be trading recall for precision, the eternal question when doing search.
At the end of the article we show how implement this in practice by making usage of the different encoders available in the phonetic analysis plugin. Advanced users, please explore what the different algorithms can give you, because you will find amazing differences by language and edge cases.
If you are setting up your new and shinny search features, improving your current search, or simply having challenges implementing great search, i am here to help, contact me for details.